After the last long blog post, here comes another in the continuing discussion of loading US Census TIGER data into PostGIS. Since the datasets here are more complex than the single national-level files, we will use some simple Bash shell scripts to process and convert the data into single state- or national-level files. So without much ado, let us continue.
Once you have uploaded all the data from the previous post into PostGIS, you can delete the files from the staging directory. You will need the space as these datasets typically measure in the hundreds of megabytes to gigabytes. Additionally, unlike the last post where we downloaded all the national-level files in one pass, here we will do a single dataset at a time to save space. Again, I am posting the state/national level converted files to my website and will post the link soon.
To begin, run lftp again and this time mirror the PRISECROADS/ directory. This dataset is a combination of basically interstates and major US highways. When done downloading, you will have 283 megabytes of zip files where each file covers a state. We will take this file and convert it to a single national file. As with the last post, I’m including the commands and their outputs below. First we will unzip all of the files inside the same directory.
[bmaddox@girls PRISECROADS]$ ls
tl_2013_01_prisecroads.zip tl_2013_23_prisecroads.zip tl_2013_42_prisecroads.zip
tl_2013_02_prisecroads.zip tl_2013_24_prisecroads.zip tl_2013_44_prisecroads.zip
tl_2013_04_prisecroads.zip tl_2013_25_prisecroads.zip tl_2013_45_prisecroads.zip
tl_2013_05_prisecroads.zip tl_2013_26_prisecroads.zip tl_2013_46_prisecroads.zip
tl_2013_06_prisecroads.zip tl_2013_27_prisecroads.zip tl_2013_47_prisecroads.zip
tl_2013_08_prisecroads.zip tl_2013_28_prisecroads.zip tl_2013_48_prisecroads.zip
tl_2013_09_prisecroads.zip tl_2013_29_prisecroads.zip tl_2013_49_prisecroads.zip
tl_2013_10_prisecroads.zip tl_2013_30_prisecroads.zip tl_2013_50_prisecroads.zip
tl_2013_11_prisecroads.zip tl_2013_31_prisecroads.zip tl_2013_51_prisecroads.zip
tl_2013_12_prisecroads.zip tl_2013_32_prisecroads.zip tl_2013_53_prisecroads.zip
tl_2013_13_prisecroads.zip tl_2013_33_prisecroads.zip tl_2013_54_prisecroads.zip
tl_2013_15_prisecroads.zip tl_2013_34_prisecroads.zip tl_2013_55_prisecroads.zip
tl_2013_16_prisecroads.zip tl_2013_35_prisecroads.zip tl_2013_56_prisecroads.zip
tl_2013_17_prisecroads.zip tl_2013_36_prisecroads.zip tl_2013_60_prisecroads.zip
tl_2013_18_prisecroads.zip tl_2013_37_prisecroads.zip tl_2013_66_prisecroads.zip
tl_2013_19_prisecroads.zip tl_2013_38_prisecroads.zip tl_2013_69_prisecroads.zip
tl_2013_20_prisecroads.zip tl_2013_39_prisecroads.zip tl_2013_72_prisecroads.zip
tl_2013_21_prisecroads.zip tl_2013_40_prisecroads.zip tl_2013_78_prisecroads.zip
tl_2013_22_prisecroads.zip tl_2013_41_prisecroads.zip
[bmaddox@girls PRISECROADS]$ for foo in *.zip; do unzip $foo; done
Archive: tl_2013_01_prisecroads.zip
inflating: tl_2013_01_prisecroads.dbf
inflating: tl_2013_01_prisecroads.prj
inflating: tl_2013_01_prisecroads.shp
inflating: tl_2013_01_prisecroads.shp.xml
inflating: tl_2013_01_prisecroads.shx
...
Archive: tl_2013_78_prisecroads.zip
inflating: tl_2013_78_prisecroads.dbf
inflating: tl_2013_78_prisecroads.prj
inflating: tl_2013_78_prisecroads.shp
inflating: tl_2013_78_prisecroads.shp.xml
inflating: tl_2013_78_prisecroads.shx
Now that the files are all in the same directory, we will use the following script called doogr.sh to convert them.
doogr.sh
#!/bin/bash
# doogr.sh
# Script to automatically create state-based shapefiles using ogr2ogr
# Grab the name of the output shapefile
shapefilename=$1
# Now grab the name of the initial input file
firstfile=$2
# make the initial state file
echo "Creating initial state shapefile $shapefilename"
ogr2ogr $shapefilename $firstfile
# Grab the basename of the firstfiles
firstfilebase=`basename $firstfile .shp`
# Grab the basename of the shapefile for ogr2ogr update
shapefilenamebase=`basename $shapefilename .shp`
# Delete the first files
echo "Now deleting the initial shapefiles to avoid duplication"
rm $firstfilebase.*
# Now make the rest of the state shape files
echo "Merging the rest of the files into the main shapefile"
for foo in tl*.shp; do
ogr2ogr -update -append $shapefilename $foo -nln $shapefilenamebase
done
This script is really simple but it works for me 🙂 You run it by typing:
doogr.sh outputshapefile.shp firstinputfile.shp
Run it in the same directory as the zipfiles you just unzipped, and the output will look similar to this:
[bmaddox@girls PRISECROADS]$ ~/bin/doogr.sh prisecroads.shp tl_2013_01_prisecroads.shp
Creating initial state shapefile prisecroads.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls PRISECROADS]$ \rm tl*
[bmaddox@girls PRISECROADS]$ ls -l
total 492676
-rw-rw-r-- 1 bmaddox bmaddox 39521375 Feb 24 19:12 prisecroads.dbf
-rw-rw-r-- 1 bmaddox bmaddox 165 Feb 24 19:12 prisecroads.prj
-rw-rw-r-- 1 bmaddox bmaddox 462516820 Feb 24 19:12 prisecroads.shp
-rw-rw-r-- 1 bmaddox bmaddox 2451028 Feb 24 19:12 prisecroads.shx
[bmaddox@girls PRISECROADS]$
You can see that after the command ran, I rm’med the zip files and their output as we no longer need them. Now putting the combined file into PostGIS is as simple as running:
[bmaddox@girls PRISECROADS]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 prisecroads.shp US_Primary_Secondary_Roads |psql -d Census_2013
Shapefile type: Arc
Postgis type: MULTILINESTRING[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_primary_secondary_roads_gid_seq" for serial column "us_primary_secondary_roads.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_primary_secondary_roads_pkey" for table "us_primary_secondary_roads"
ALTER TABLE
addgeometrycolumn
-------------------------------------------------------------------------------
public.us_primary_secondary_roads.geom SRID:4269 TYPE:MULTILINESTRING DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls PRISECROADS]$
When finished, the file in PostGIS should look like this:
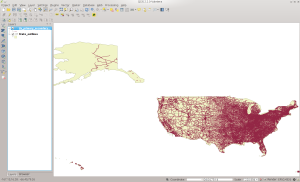
PRISECROADS in QGIS
Next we move on to the BG directory, which contains the state-based Census block groups. Run lftp and mirror the BG directory. Change to BG and run the unzip command that you did earlier to unzip all of the files into the same directory. Then run the doogr.sh command in this directory and your output will look similar to the below:
[bmaddox@girls BG]$ doogr.sh us_census_bg.shp tl_2013_01_bg.shp
Creating initial state shapefile us_census_bg.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls BG]$ \rm tl*
[bmaddox@girls BG]$ ls -l
total 1074972
-rw-rw-r-- 1 bmaddox bmaddox 20970717 Mar 2 11:45 us_census_bg.dbf
-rw-rw-r-- 1 bmaddox bmaddox 165 Mar 2 11:45 us_census_bg.prj
-rw-rw-r-- 1 bmaddox bmaddox 1078018856 Mar 2 11:45 us_census_bg.shp
-rw-rw-r-- 1 bmaddox bmaddox 1766020 Mar 2 11:45 us_census_bg.shx
[bmaddox@girls BG]$
To add the now national-level Shapefile, run the following command:
[bmaddox@girls BG]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 us_census_bg.shp US_Census_Block_Groups |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_census_block_groups_gid_seq" for serial column "us_census_block_groups.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_census_block_groups_pkey" for table "us_census_block_groups"
ALTER TABLE
addgeometrycolumn
------------------------------------------------------------------------
public.us_census_block_groups.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls BG]$
The data will look similar to this in QGIS:
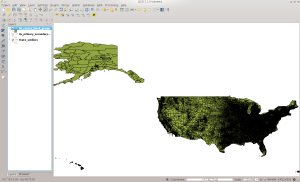
BG in QGIS
Next move on to the ELSD directory, that contains Elementary School Districts that the Census recognizes. Again, run lftp and mirror the ELSD directory. Then change into ELSD and run commands similar to below:
[bmaddox@girls ELSD]$ doogr.sh us_elsd.shp tl_2013_04_elsd.shp
Creating initial state shapefile us_elsd.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls ELSD]$ ls -l us_elsd.*
-rw-rw-r-- 1 bmaddox bmaddox 390701 Mar 2 12:17 us_elsd.dbf
-rw-rw-r-- 1 bmaddox bmaddox 165 Mar 2 12:17 us_elsd.prj
-rw-rw-r-- 1 bmaddox bmaddox 21617064 Mar 2 12:17 us_elsd.shp
-rw-rw-r-- 1 bmaddox bmaddox 17540 Mar 2 12:17 us_elsd.shx
[bmaddox@girls ELSD]$ shp2pgsql -s 4269 -c -D -I us_elsd.shp US_Elementary_School_Districts |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_elementary_school_districts_gid_seq" for serial column "us_elementary_school_districts.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_elementary_school_districts_pkey" for table "us_elementary_school_districts"
ALTER TABLE
addgeometrycolumn
--------------------------------------------------------------------------------
public.us_elementary_school_districts.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls ELSD]$
And this dataset will look like this in QGIS:
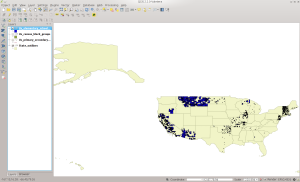
ELSD in QGIS
Moving on, now run lftp and mirror the SCSD and UNSD directories. These are the Secondary School Districts and Unified School Districts, respectively. Change to your SCSD directory and unzip all of the files there. As you should be getting the hang of this now, here are the commands and their output once you have unzipped the tl* files.
[bmaddox@girls SCSD]$ doogr.sh us_scsd.shp tl_2013_04_scsd.shp
Creating initial state shapefile us_scsd.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls SCSD]$ ls -l us_scsd.*
-rw-rw-r-- 1 bmaddox bmaddox 93561 Mar 2 12:26 us_scsd.dbf
-rw-rw-r-- 1 bmaddox bmaddox 165 Mar 2 12:26 us_scsd.prj
-rw-rw-r-- 1 bmaddox bmaddox 10783856 Mar 2 12:26 us_scsd.shp
-rw-rw-r-- 1 bmaddox bmaddox 4260 Mar 2 12:26 us_scsd.shx
[bmaddox@girls SCSD]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 us_scsd.shp US_Secondary_School_Districts |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_secondary_school_districts_gid_seq" for serial column "us_secondary_school_districts.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_secondary_school_districts_pkey" for table "us_secondary_school_districts"
ALTER TABLE
addgeometrycolumn
-------------------------------------------------------------------------------
public.us_secondary_school_districts.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls SCSD]$
And in QGIS:
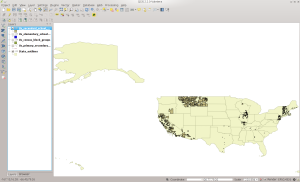
SCSD in QGIS
Next change to the UNSD directory, unzip the files, and run the commands as seen below:
[bmaddox@girls UNSD]$ doogr.sh us_unsd.shp tl_2013_01_unsd.shp
Creating initial state shapefile us_unsd.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls UNSD]$ \rm tl*
[bmaddox@girls UNSD]$ ls -l
total 216652
-rw-rw-r-- 1 bmaddox bmaddox 1958025 Mar 2 12:31 us_unsd.dbf
-rw-rw-r-- 1 bmaddox bmaddox 165 Mar 2 12:31 us_unsd.prj
-rw-rw-r-- 1 bmaddox bmaddox 219793844 Mar 2 12:31 us_unsd.shp
-rw-rw-r-- 1 bmaddox bmaddox 87588 Mar 2 12:31 us_unsd.shx
[bmaddox@girls UNSD]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 us_unsd.shp US_Unified_School_Districts |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_unified_school_districts_gid_seq" for serial column "us_unified_school_districts.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_unified_school_districts_pkey" for table "us_unified_school_districts"
ALTER TABLE
addgeometrycolumn
-----------------------------------------------------------------------------
public.us_unified_school_districts.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls UNSD]$
And in QGIS:
UNSD in QGIS
Next, run lftp and mirror the SLDL and SLDU directories. These are the State Legislative District Lower and Upper datasets. Go into SLDL, unzip the files, and run these commands:
[bmaddox@girls SLDL]$ doogr.sh us_sldl.shp tl_2013_01_sldl.shp
Creating initial state shapefile us_sldl.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls SLDL]$ \rm tl*
[bmaddox@girls SLDL]$ ls -l
total 210476
-rw-rw-r-- 1 bmaddox bmaddox 841533 Mar 2 12:39 us_sldl.dbf
-rw-rw-r-- 1 bmaddox bmaddox 165 Mar 2 12:39 us_sldl.prj
-rw-rw-r-- 1 bmaddox bmaddox 214636500 Mar 2 12:39 us_sldl.shp
-rw-rw-r-- 1 bmaddox bmaddox 38772 Mar 2 12:39 us_sldl.shx
[bmaddox@girls SLDL]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 us_sldl.shp US_State_Legislative_Lower |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_state_legislative_lower_gid_seq" for serial column "us_state_legislative_lower.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_state_legislative_lower_pkey" for table "us_state_legislative_lower"
ALTER TABLE
addgeometrycolumn
----------------------------------------------------------------------------
public.us_state_legislative_lower.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls SLDL]$
And in QGIS:
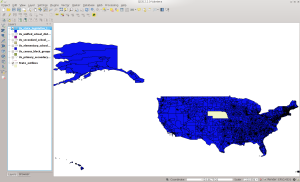
SLDL in QGIS
BTW, something did not go wrong if you notice that there is no data for Nebraska. It has a unicameral form of government, which means it is not split into a House and Senate.
Next, change to the SLDU directory, unzip the files, and run the following commands:
[bmaddox@girls SLDU]$ doogr.sh us_sldu.shp tl_2013_01_sldu.shp
Creating initial state shapefile us_sldu.shp
Now deleting the initial shapefiles to avoid duplication
Merging the rest of the files into the main shapefile
[bmaddox@girls SLDU]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 us_sldu.shp US_State_Legislative_Upper |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_state_legislative_upper_gid_seq" for serial column "us_state_legislative_upper.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_state_legislative_upper_pkey" for table "us_state_legislative_upper"
ALTER TABLE
addgeometrycolumn
----------------------------------------------------------------------------
public.us_state_legislative_upper.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls SLDU]$
And in QGIS:
SLDU in QGIS
I’m going to end this now so it is not as crazy long as the previous post was. Next time we will work on the biggies of the Census datasets: roads, linearwater, areawater, and landmarks.








