In Part 8.1, we went over how the Census ftp site was set up and what kind of data each directory has in it. We also loaded our first Census data, which were outlines of the US states and territories. In this installment, we will load all the national files on the Census FTP site. These are all individual files so will be easier to load. Next time we will look at using scripts to convert the rest of the county-based data into state-based datasets.
We are not going to download everything on the Census website. Some of the data you will likely never need. However, once these articles are done you should be able to download and create tables from the other data directories should you decide you need them. After each load, I will show a screen shot of how the data table looks inside QGIS so you can make sure everything loaded properly.
This is a rather lengthy post as it shows the commands you should type as well as the output so you can check that what you are doing works correctly. Be glad I do not sell advertising or this would be spread across many pages 😉
For this set aside some time as the Census ftp site limits connection speeds to keep people from using up all of their bandwidth. Open a shell prompt, change to a directory where you will download the data, and run the command:
lftp ftp://ftp2.census.gov/geo/tiger/TIGER2013
Type the command cls and you will see this listing:
lftp ftp2.census.gov:/geo/tiger/TIGER2013> cls
2013-FolderNames-Defined.pdf AREAWATER/ COUSUB/ FACESMIL/ PLACE/ SLDL/ UAC/
ADDR/ BG/ CSA/ FEATNAMES/ POINTLM/ SLDU/ UNSD/
ADDRFEAT/ CBSA/ EDGES/ LINEARWATER/ PRIMARYROADS/ STATE/ ZCTA5/
ADDRFN/ CD/ ELSD/ METDIV/ PRISECROADS/ SUBMCD/
AIANNH/ CNECTA/ ESTATE/ MIL/ PUMA/ TABBLOCK/
AITS/ COAST/ FACES/ NECTA/ RAILS/ TBG/
ANRC/ CONCITY/ FACESAH/ NECTADIV/ ROADS/ TRACT/
AREALM/ COUNTY/ FACESAL/ OTHERID/ SCSD/ TTRACT/
lftp ftp2.census.gov:/geo/tiger/TIGER2013>
Here we will download the datasets that come in single national-level files from the Census. Run the following commands inside lftp, waiting for each to finish:
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror COUNTY/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror AIANNH/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror AITS/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror ANRC/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror CBSA/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror CD/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror CNECTA/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror COAST/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror ESTATE/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror METDIV/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror MIL/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror NECTA/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror NECTADIV/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror PRIMARYROADS/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror RAILS/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror TBG/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror UAC/
lftp ftp2.census.gov:/geo/tiger/TIGER2013> mirror ZCTA5/
This gives you a good number of files to add to your database for this part of the series. Type quit or hit Control-D to exit lftp.
We will start with the files under COUNTY as this will give you the county outlines to match the state outlines you loaded during the last installment. Change directory (cd) into the COUNTY directory and unzip the tl_2013_us_county.zip file:
[bmaddox@girls COUNTY]$ unzip tl_2013_us_county.zip
Archive: tl_2013_us_county.zip
inflating: tl_2013_us_county.dbf
inflating: tl_2013_us_county.prj
inflating: tl_2013_us_county.shp
inflating: tl_2013_us_county.shp.xml
inflating: tl_2013_us_county.shx
[bmaddox@girls COUNTY]$ ls -l
total 188336
-rwxrwxr-x 1 bmaddox bmaddox 948140 Aug 6 2013 tl_2013_us_county.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_county.prj
-rwxrwxr-x 1 bmaddox bmaddox 118339660 Aug 6 2013
tl_2013_us_county.shp
-rwxrwxr-x 1 bmaddox bmaddox 24960 Aug 6 2013
tl_2013_us_county.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 25972 Aug 6 2013 tl_2013_us_county.shx
-rwxrw-r-x 1 bmaddox bmaddox 73500446 Aug 16 2013
tl_2013_us_county.zip
[bmaddox@girls COUNTY]$
Now run the command:
shp2pgsql -s 4269 -c -D -I -W LATIN1 tl_2013_us_county.shp county_outlines |psql -d Census_2013
Your command will look similar to the following output. Here I am running the import commands on the same server that is hosting the database.
[bmaddox@girls COUNTY]$ shp2pgsql -s 4269 -c -D -I -W LATIN1 tl_2013_us_county.shp county_outlines |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence
"county_outlines_gid_seq" for serial column "county_outlines.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index
"county_outlines_pkey" for table "county_outlines"
ALTER TABLE
addgeometrycolumn
-----------------------------------------------------------------
public.county_outlines.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls COUNTY]$
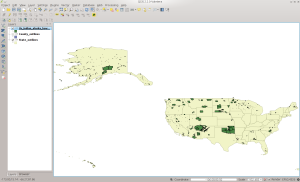
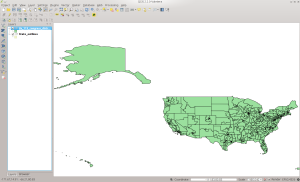
Run QGIS and load the state table that you created in the last installment. Once that finishes, add the county_outlines layer. Once loaded, it should look like this screen shot:
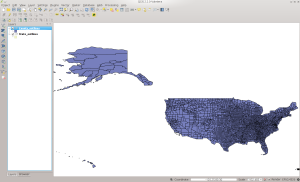
US County Outlines in QGIS
Now change to the AIANNH directory. This is the American Indian / Alaska Native / Native Hawaiian Areas dataset. This data contains information such as land and water area in each regional corporation. Run the following commands to unzip and load the data into PostGIS, substituting values specific to your setup:
[bmaddox@girls AIANNH]$ unzip tl_2013_us_aiannh.zip
Archive: tl_2013_us_aiannh.zip
inflating: tl_2013_us_aiannh.dbf
inflating: tl_2013_us_aiannh.prj
inflating: tl_2013_us_aiannh.shp
inflating: tl_2013_us_aiannh.shp.xml
inflating: tl_2013_us_aiannh.shx
[bmaddox@girls AIANNH]$ ls -l
total 21576
-rwxrwxr-x 1 bmaddox bmaddox 232620 Aug 6 2013 tl_2013_us_aiannh.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_aiannh.prj
-rwxrwxr-x 1 bmaddox bmaddox 13362524 Aug 6 2013 tl_2013_us_aiannh.shp
-rwxrwxr-x 1 bmaddox bmaddox 31978 Aug 6 2013
tl_2013_us_aiannh.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 6708 Aug 6 2013 tl_2013_us_aiannh.shx
-rwxrw-r-x 1 bmaddox bmaddox 8447076 Aug 16 2013 tl_2013_us_aiannh.zip
[bmaddox@girls AIANNH]$ shp2pgsql -s 4269 -c -D -I
tl_2013_us_aiannh.shp US_Indian_Alaska_Hawaii_Native_Areas |psql -d
Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence
"us_indian_alaska_hawaii_native_areas_gid_seq" for serial column
"us_indian_alaska_hawaii_native_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index
"us_indian_alaska_hawaii_native_areas_pkey" for table
"us_indian_alaska_hawaii_native_areas"
ALTER TABLE
addgeometrycolumn
----------------------------------------------------------------------
----------------
public.us_indian_alaska_hawaii_native_areas.geom SRID:4269
TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls AIANNH]$
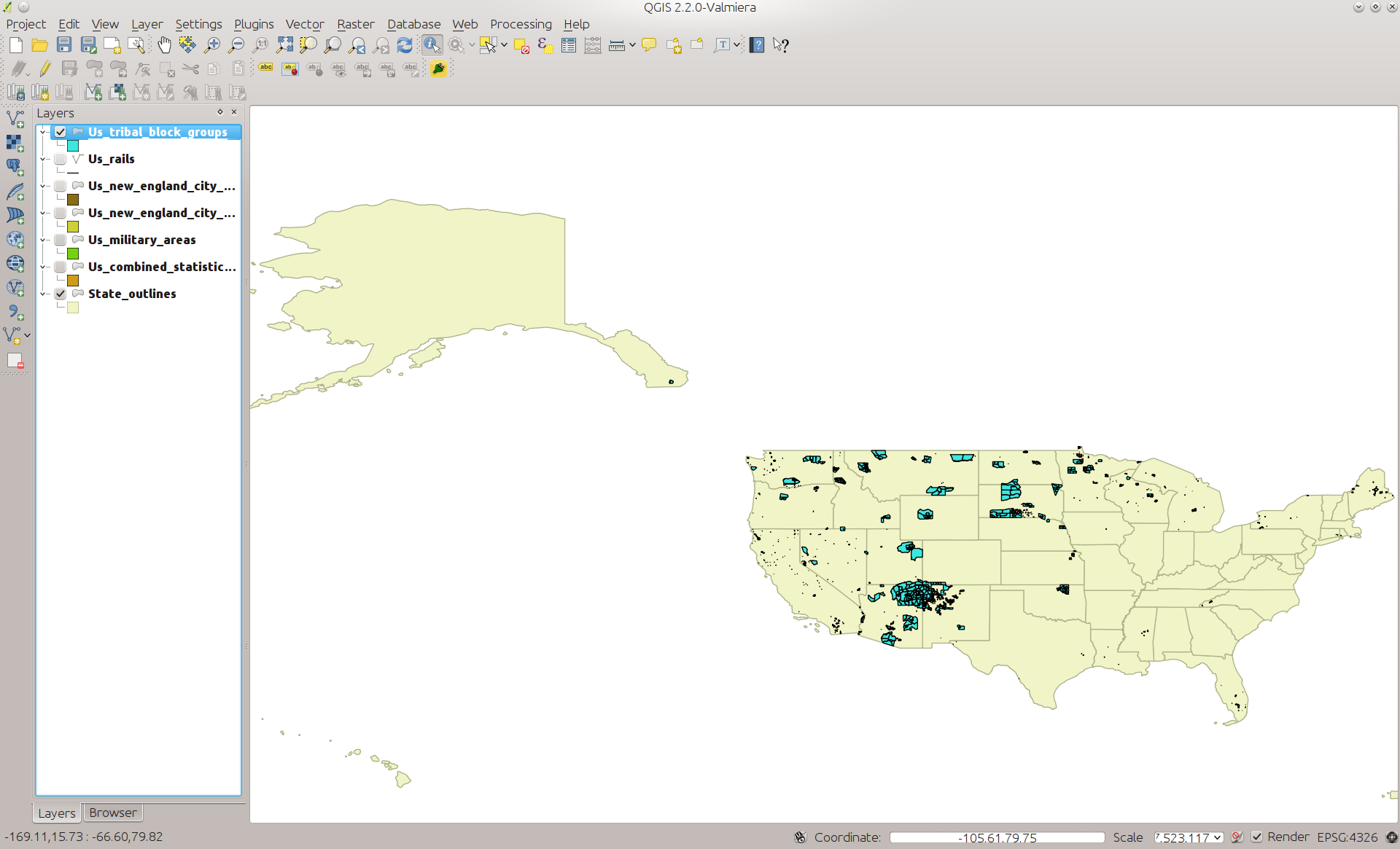
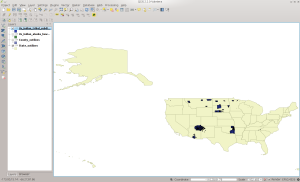
The loaded data should look similar to the screen shot below:
AIANNH Dataset
Next change to the AITS directory. This is the American Indian Tribal Subdivision dataset. It contains information similar to the AIANNH dataset. Since the technique should be familiar now, here are the commands to run and their output. Again, substitute the specific values applicable to your setup.
[bmaddox@girls census]$ cd AITS/
[bmaddox@girls AITS]$ ls
tl_2013_us_aitsn.zip
[bmaddox@girls AITS]$ unzip tl_2013_us_aitsn.zip
Archive: tl_2013_us_aitsn.zip
inflating: tl_2013_us_aitsn.dbf
inflating: tl_2013_us_aitsn.prj
inflating: tl_2013_us_aitsn.shp
inflating: tl_2013_us_aitsn.shp.xml
inflating: tl_2013_us_aitsn.shx
[bmaddox@girls AITS]$ ls -l
total 14900
-rwxrwxr-x 1 bmaddox bmaddox 134814 Aug 6 2013 tl_2013_us_aitsn.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_aitsn.prj
-rwxrwxr-x 1 bmaddox bmaddox 9291396 Aug 6 2013 tl_2013_us_aitsn.shp
-rwxrwxr-x 1 bmaddox bmaddox 21736 Aug 6 2013 tl_2013_us_aitsn.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 3884 Aug 6 2013 tl_2013_us_aitsn.shx
-rwxrw-r-x 1 bmaddox bmaddox 5794063 Aug 16 2013 tl_2013_us_aitsn.zip
[bmaddox@girls AITS]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_aitsn.shp US_Indian_Tribal_Subdivisions |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_indian_tribal_subdivisions_gid_seq" for serial column "us_indian_tribal_subdivisions.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_indian_tribal_subdivisions_pkey" for table "us_indian_tribal_subdivisions"
ALTER TABLE
addgeometrycolumn
-------------------------------------------------------------------------------
public.us_indian_tribal_subdivisions.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls AITS]$
The dataset should look like the following screen shot in QGIS:
AITS Dataset
Next up is the Alaska Native Regional Corporations dataset. As with the other datasets, here are the commands you will use to load the data into PostGIS:
[bmaddox@girls census]$ cd ANRC
[bmaddox@girls ANRC]$ ls -l
total 752
-rwxrw-r-x 1 bmaddox bmaddox 768407 Aug 16 2013 tl_2013_02_anrc.zip
[bmaddox@girls ANRC]$ unzip tl_2013_02_anrc.zip
Archive: tl_2013_02_anrc.zip
inflating: tl_2013_02_anrc.dbf
inflating: tl_2013_02_anrc.prj
inflating: tl_2013_02_anrc.shp
inflating: tl_2013_02_anrc.shp.xml
inflating: tl_2013_02_anrc.shx
[bmaddox@girls ANRC]$ ls -l
total 1896
-rwxrwxr-x 1 bmaddox bmaddox 3890 Aug 6 2013 tl_2013_02_anrc.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_02_anrc.prj
-rwxrwxr-x 1 bmaddox bmaddox 1131900 Aug 6 2013 tl_2013_02_anrc.shp
-rwxrwxr-x 1 bmaddox bmaddox 21487 Aug 6 2013 tl_2013_02_anrc.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 196 Aug 6 2013 tl_2013_02_anrc.shx
-rwxrw-r-x 1 bmaddox bmaddox 768407 Aug 16 2013 tl_2013_02_anrc.zip
[bmaddox@girls ANRC]$ shp2pgsql -s 4269 -c -D -I tl_2013_02_anrc.shp US_Alaska_Native_Regional_Corporations |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_alaska_native_regional_corporations_gid_seq" for serial column "us_alaska_native_regional_corporations.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_alaska_native_regional_corporations_pkey" for table "us_alaska_native_regional_corporations"
ALTER TABLE
addgeometrycolumn ----------------------------------------------------------------------------------------
public.us_alaska_native_regional_corporations.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls ANRC]$
Here is the screenshot of how the data should look in QGIS:
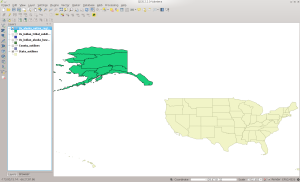
ANRC Dataset
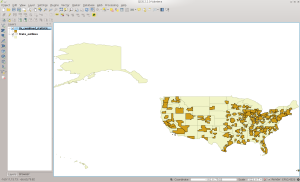
Next change to the CBSA directory. This contains the combined Metropolitan and Micropolitan statistical areas. As before, here are the commands and you will replace things with information specific to your setup:
[bmaddox@girls census]$ cd CBSA/
[bmaddox@girls CBSA]$ ls -l
total 28960
-rwxrw-r-x 1 bmaddox bmaddox 29654427 Aug 16 2013 tl_2013_us_cbsa.zip
[bmaddox@girls CBSA]$ unzip tl_2013_us_cbsa.zip
Archive: tl_2013_us_cbsa.zip
inflating: tl_2013_us_cbsa.dbf
inflating: tl_2013_us_cbsa.prj
inflating: tl_2013_us_cbsa.shp
inflating: tl_2013_us_cbsa.shp.xml
inflating: tl_2013_us_cbsa.shx
[bmaddox@girls CBSA]$ ls -l
total 75708
-rwxrwxr-x 1 bmaddox bmaddox 254035 Aug 6 2013 tl_2013_us_cbsa.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_cbsa.prj
-rwxrwxr-x 1 bmaddox bmaddox 47575788 Aug 6 2013 tl_2013_us_cbsa.shp
-rwxrwxr-x 1 bmaddox bmaddox 17767 Aug 6 2013 tl_2013_us_cbsa.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 7532 Aug 6 2013 tl_2013_us_cbsa.shx
-rwxrw-r-x 1 bmaddox bmaddox 29654427 Aug 16 2013 tl_2013_us_cbsa.zip
[bmaddox@girls CBSA]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_cbsa.shp US_Metro_Micropolitan_Statistical_Areas |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_metro_micropolitan_statistical_areas_gid_seq" for serial column "us_metro_micropolitan_statistical_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_metro_micropolitan_statistical_areas_pkey" for table "us_metro_micropolitan_statistical_areas"
ALTER TABLE
addgeometrycolumn
-----------------------------------------------------------------------------------------
public.us_metro_micropolitan_statistical_areas.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls CBSA]$
Here is how it looks in QGIS once loaded:
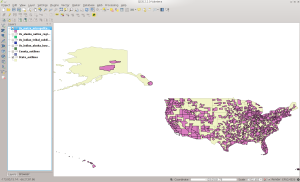
CBSA in QGIS
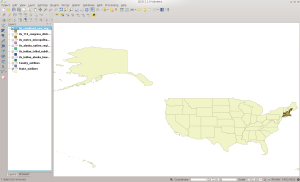
Now change to the CD directory. This dataset contains the 113th Congress Congressional districts.
[bmaddox@girls census]$ ls CD
tl_2013_us_cd113.zip
[bmaddox@girls census]$ cd CD/
[bmaddox@girls CD]$ ls -l
total 38528
-rwxrw-r-x 1 bmaddox bmaddox 39448037 Aug 16 2013 tl_2013_us_cd113.zip
[bmaddox@girls CD]$ unzip tl_2013_us_cd113.zip
Archive: tl_2013_us_cd113.zip
inflating: tl_2013_us_cd113.dbf
inflating: tl_2013_us_cd113.prj
inflating: tl_2013_us_cd113.shp
inflating: tl_2013_us_cd113.shp.xml
inflating: tl_2013_us_cd113.shx
[bmaddox@girls CD]$ ls -l
total 100132
-rwxrwxr-x 1 bmaddox bmaddox 50146 Aug 6 2013 tl_2013_us_cd113.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_cd113.prj
-rwxrwxr-x 1 bmaddox bmaddox 62997500 Aug 6 2013 tl_2013_us_cd113.shp
-rwxrwxr-x 1 bmaddox bmaddox 19400 Aug 6 2013 tl_2013_us_cd113.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 3652 Aug 6 2013 tl_2013_us_cd113.shx
-rwxrw-r-x 1 bmaddox bmaddox 39448037 Aug 16 2013 tl_2013_us_cd113.zip
[bmaddox@girls CD]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_cd113.shp US_113_Congress_Districts |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_113_congress_districts_gid_seq" for serial column "us_113_congress_districts.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_113_congress_districts_pkey" for table "us_113_congress_districts"
ALTER TABLE
addgeometrycolumn
---------------------------------------------------------------------------
public.us_113_congress_districts.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls CD]$
113th Congressional Districts
Now we move to the CNECTA directory. This dataset is the Combined New England City and Town Areas dataset.
[bmaddox@girls census]$ ls CNECTA/
tl_2013_us_cnecta.zip
[bmaddox@girls census]$ cd CNECTA/
[bmaddox@girls CNECTA]$ ls -l
total 436
-rwxrw-r-x 1 bmaddox bmaddox 442433 Aug 16 2013 tl_2013_us_cnecta.zip
[bmaddox@girls CNECTA]$ unzip tl_2013_us_cnecta.zip
Archive: tl_2013_us_cnecta.zip
inflating: tl_2013_us_cnecta.dbf
inflating: tl_2013_us_cnecta.prj
inflating: tl_2013_us_cnecta.shp
inflating: tl_2013_us_cnecta.shp.xml
inflating: tl_2013_us_cnecta.shx
[bmaddox@girls CNECTA]$ ls -l
total 1128
-rwxrwxr-x 1 bmaddox bmaddox 1944 Aug 6 2013 tl_2013_us_cnecta.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_cnecta.prj
-rwxrwxr-x 1 bmaddox bmaddox 679436 Aug 6 2013 tl_2013_us_cnecta.shp
-rwxrwxr-x 1 bmaddox bmaddox 16353 Aug 6 2013 tl_2013_us_cnecta.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 148 Aug 6 2013 tl_2013_us_cnecta.shx
-rwxrw-r-x 1 bmaddox bmaddox 442433 Aug 16 2013 tl_2013_us_cnecta.zip
[bmaddox@girls CNECTA]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_cnecta.shp US_Combined_New_England_City_Town_Areas |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_combined_new_england_city_town_areas_gid_seq" for serial column "us_combined_new_england_city_town_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_combined_new_england_city_town_areas_pkey" for table "us_combined_new_england_city_town_areas"
ALTER TABLE
addgeometrycolumn
-----------------------------------------------------------------------------------------
public.us_combined_new_england_city_town_areas.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls CNECTA]$
The loaded data should look similar to below:
CNECTA Dataset
Next we move on to the COAST directory. This is the US Coastline data derived from Census edges.
[bmaddox@girls census]$ ls COAST/
tl_2013_us_coastline.zip
[bmaddox@girls census]$ cd COAST/
[bmaddox@girls COAST]$ ls -l
total 15792
-rwxrw-r-x 1 bmaddox bmaddox 16168901 Aug 16 2013 tl_2013_us_coastline.zip
[bmaddox@girls COAST]$ unzip tl_2013_us_coastline.zip
Archive: tl_2013_us_coastline.zip
inflating: tl_2013_us_coastline.dbf
inflating: tl_2013_us_coastline.prj
inflating: tl_2013_us_coastline.shp
inflating: tl_2013_us_coastline.shp.xml
inflating: tl_2013_us_coastline.shx
[bmaddox@girls COAST]$ ls -l
total 40272
-rwxrwxr-x 1 bmaddox bmaddox 449644 Aug 6 2013 tl_2013_us_coastline.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_coastline.prj
-rwxrwxr-x 1 bmaddox bmaddox 24558540 Aug 6 2013 tl_2013_us_coastline.shp
-rwxrwxr-x 1 bmaddox bmaddox 15352 Aug 7 2013 tl_2013_us_coastline.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 34028 Aug 6 2013 tl_2013_us_coastline.shx
-rwxrw-r-x 1 bmaddox bmaddox 16168901 Aug 16 2013 tl_2013_us_coastline.zip
[bmaddox@girls COAST]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_coastline.shp US_Coastlines |psql -d Census_2013
Shapefile type: Arc
Postgis type: MULTILINESTRING[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_coastlines_gid_seq" for serial column "us_coastlines.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_coastlines_pkey" for table "us_coastlines"
ALTER TABLE
addgeometrycolumn
------------------------------------------------------------------
public.us_coastlines.geom SRID:4269 TYPE:MULTILINESTRING DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls COAST]$
The coastlines will look like this:

COAST in QGIS
We now move to the CSA directory, which holds the combined statistical area national-level shapefile. These are generally areas where several large cities are combined into a single statistical unit, such as the Branson-Springfield area in Missouri.
[bmaddox@girls census]$ ls CSA
tl_2013_us_csa.zip
[bmaddox@girls census]$ cd CSA/
[bmaddox@girls CSA]$ ls -l
total 10020
-rwxrw-r-x 1 bmaddox bmaddox 10259685 Aug 16 2013 tl_2013_us_csa.zip [bmaddox@girls CSA]$ unzip tl_2013_us_csa.zip
Archive: tl_2013_us_csa.zip
inflating: tl_2013_us_csa.dbf
inflating: tl_2013_us_csa.prj
inflating: tl_2013_us_csa.shp
inflating: tl_2013_us_csa.shp.xml
inflating: tl_2013_us_csa.shx
[bmaddox@girls CSA]$ ls -l
total 26184
-rwxrwxr-x 1 bmaddox bmaddox 45139 Aug 6 2013 tl_2013_us_csa.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_csa.prj
-rwxrwxr-x 1 bmaddox bmaddox 16477264 Aug 6 2013 tl_2013_us_csa.shp -rwxrwxr-x 1 bmaddox bmaddox 16012 Aug 6 2013 tl_2013_us_csa.shp.xml -rwxrwxr-x 1 bmaddox bmaddox 1452 Aug 6 2013 tl_2013_us_csa.shx
-rwxrw-r-x 1 bmaddox bmaddox 10259685 Aug 16 2013 tl_2013_us_csa.zip [bmaddox@girls CSA]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_csa.shp US_Combined_Statistical_Areas |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_combined_statistical_areas_gid_seq" for serial column "us_combined_statistical_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_combined_statistical_areas_pkey" for table "us_combined_statistical_areas"
ALTER TABLE
addgeometrycolumn
-------------------------------------------------------------------------------
public.us_combined_statistical_areas.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls CSA]$
Once loaded, it should look like this in QGIS:
CSA in QGIS
The MIL directory contains areas that are classified as belonging to the US Military… that we know about at least.
[bmaddox@girls census]$ cd MIL/
[bmaddox@girls MIL]$ dir
total 2904
-rwxrw-r-x 1 bmaddox bmaddox 2973061 Aug 16 2013 tl_2013_us_mil.zip
[bmaddox@girls MIL]$ unzip tl_2013_us_mil.zip
Archive: tl_2013_us_mil.zip
inflating: tl_2013_us_mil.dbf
inflating: tl_2013_us_mil.prj
inflating: tl_2013_us_mil.shp
inflating: tl_2013_us_mil.shp.xml
inflating: tl_2013_us_mil.shx
[bmaddox@girls MIL]$ ls -l
total 7628
-rwxrwxr-x 1 bmaddox bmaddox 150451 Aug 6 2013 tl_2013_us_mil.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_mil.prj
-rwxrwxr-x 1 bmaddox bmaddox 4653712 Aug 6 2013 tl_2013_us_mil.shp
-rwxrwxr-x 1 bmaddox bmaddox 15575 Aug 6 2013 tl_2013_us_mil.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 6524 Aug 6 2013 tl_2013_us_mil.shx
-rwxrw-r-x 1 bmaddox bmaddox 2973061 Aug 16 2013 tl_2013_us_mil.zip
[bmaddox@girls MIL]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_mil.shp US_Military_Areas |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_military_areas_gid_seq" for serial column "us_military_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_military_areas_pkey" for table "us_military_areas"
ALTER TABLE
addgeometrycolumn
-------------------------------------------------------------------
public.us_military_areas.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls MIL]$
And it looks like this in QGIS:
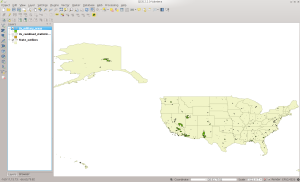
MIL in QGIS
Now to NECTA, which is the New England City and Town Areas.
[bmaddox@girls census]$ cd NECTA
[bmaddox@girls NECTA]$ ls
tl_2013_us_necta.zip
[bmaddox@girls NECTA]$ unzip tl_2013_us_necta.zip
Archive: tl_2013_us_necta.zip
inflating: tl_2013_us_necta.dbf
inflating: tl_2013_us_necta.prj
inflating: tl_2013_us_necta.shp
inflating: tl_2013_us_necta.shp.xml
inflating: tl_2013_us_necta.shx
[bmaddox@girls NECTA]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_necta.shp US_New_England_City_Town_Areas |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_new_england_city_town_areas_gid_seq" for serial column "us_new_england_city_town_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_new_england_city_town_areas_pkey" for table "us_new_england_city_town_areas"
ALTER TABLE
addgeometrycolumn
--------------------------------------------------------------------------------
public.us_new_england_city_town_areas.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls NECTA]$
Which looks like this in QGIS:
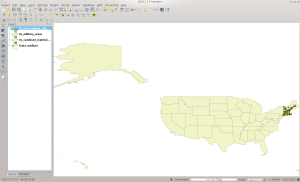
NECTA in QGIS
And the NECTADIV, which are the divisions in the NECTA dataset.
[bmaddox@girls census]$ cd NECTADIV/
[bmaddox@girls NECTADIV]$ dir
total 184
-rwxrw-r-x 1 bmaddox bmaddox 186486 Aug 16 2013 tl_2013_us_nectadiv.zip
[bmaddox@girls NECTADIV]$ unzip tl_2013_us_nectadiv.zip
Archive: tl_2013_us_nectadiv.zip
inflating: tl_2013_us_nectadiv.dbf
inflating: tl_2013_us_nectadiv.prj
inflating: tl_2013_us_nectadiv.shp
inflating: tl_2013_us_nectadiv.shp.xml
inflating: tl_2013_us_nectadiv.shx
[bmaddox@girls NECTADIV]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_nectadiv.shp US_New_England_City_Town_Divisions |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_new_england_city_town_divisions_gid_seq" for serial column "us_new_england_city_town_divisions.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_new_england_city_town_divisions_pkey" for table "us_new_england_city_town_divisions"
ALTER TABLE
addgeometrycolumn
------------------------------------------------------------------------------------
public.us_new_england_city_town_divisions.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls NECTADIV]$
QGIS Screenshot:
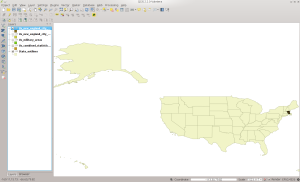
NECTADIV in QGIS
RAILS contains, you guessed it, the national-level file of US railroads.
[bmaddox@girls RAILS]$ dir
total 40660
-rwxrw-r-x 1 bmaddox bmaddox 41634270 Aug 16 2013 tl_2013_us_rails.zip
[bmaddox@girls RAILS]$ unzip tl_2013_us_rails.zip
Archive: tl_2013_us_rails.zip
inflating: tl_2013_us_rails.dbf
inflating: tl_2013_us_rails.prj
inflating: tl_2013_us_rails.shp
inflating: tl_2013_us_rails.shp.xml
inflating: tl_2013_us_rails.shx
[bmaddox@girls RAILS]$ ls -l
total 130320
-rwxrwxr-x 1 bmaddox bmaddox 23419778 Aug 6 2013 tl_2013_us_rails.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_rails.prj
-rwxrwxr-x 1 bmaddox bmaddox 66902500 Aug 6 2013 tl_2013_us_rails.shp
-rwxrwxr-x 1 bmaddox bmaddox 15759 Aug 6 2013 tl_2013_us_rails.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 1463828 Aug 6 2013 tl_2013_us_rails.shx
-rwxrw-r-x 1 bmaddox bmaddox 41634270 Aug 16 2013 tl_2013_us_rails.zip
[bmaddox@girls RAILS]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_rails.shp US_Rails |psql -d Census_2013
Shapefile type: Arc
Postgis type: MULTILINESTRING[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_rails_gid_seq" for serial column "us_rails.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_rails_pkey" for table "us_rails"
ALTER TABLE
addgeometrycolumn
-------------------------------------------------------------
public.us_rails.geom SRID:4269 TYPE:MULTILINESTRING DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls RAILS]$
In QGIS:
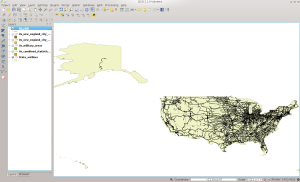
RAILS in QGIS
Next is TBG, which are national-level Tribal Block Groups.
[bmaddox@girls census]$ cd TBG/
[bmaddox@girls TBG]$ ls -l
total 16208
-rwxrwxr-x 1 bmaddox bmaddox 90939 Aug 6 2013 tl_2013_us_tbg.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_tbg.prj
rwxrwxr-x 1 bmaddox bmaddox 16468896 Aug 6 2013 tl_2013_us_tbg.shp
-rwxrwxr-x 1 bmaddox bmaddox 17719 Aug 6 2013 tl_2013_us_tbg.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 7420 Aug 6 2013 tl_2013_us_tbg.shx
[bmaddox@girls TBG]$ shp2pgsql -s 4269 -c -D -I tl_2013_us_tbg.shp US_Tribal_Block_Groups |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_tribal_block_groups_gid_seq" for serial column "us_tribal_block_groups.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_tribal_block_groups_pkey" for table "us_tribal_block_groups"
ALTER TABLE
addgeometrycolumn
------------------------------------------------------------------------
public.us_tribal_block_groups.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls TBG]$
In QGIS:
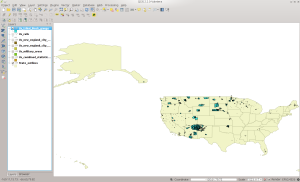
TBG in QGIS
UAC contains the Urban Areas from the 2010 Census.
[bmaddox@girls census]$ cd UAC
[bmaddox@girls UAC]$ unzip tl_2013_us_uac10.zip
Archive: tl_2013_us_uac10.zip
inflating: tl_2013_us_uac10.dbf
inflating: tl_2013_us_uac10.prj
inflating: tl_2013_us_uac10.shp
inflating: tl_2013_us_uac10.shp.xml
inflating: tl_2013_us_uac10.shx
[bmaddox@girls UAC]$ ls -l
total 211884
-rwxrwxr-x 1 bmaddox bmaddox 976289 Jul 26 2013 tl_2013_us_uac10.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Jul 26 2013 tl_2013_us_uac10.prj
-rwxrwxr-x 1 bmaddox bmaddox 132331308 Jul 26 2013 tl_2013_us_uac10.shp
-rwxrwxr-x 1 bmaddox bmaddox 17734 Aug 2 2013 tl_2013_us_uac10.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 28908 Jul 26 2013 tl_2013_us_uac10.shx
-rwxrw-r-x 1 bmaddox bmaddox 83595662 Aug 16 2013 tl_2013_us_uac10.zip
[bmaddox@girls UAC]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_uac10.shp US_Urban_Areas_2010 |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_urban_areas_2010_gid_seq" for serial column "us_urban_areas_2010.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_urban_areas_2010_pkey" for table "us_urban_areas_2010"
ALTER TABLE
addgeometrycolumn
---------------------------------------------------------------------
public.us_urban_areas_2010.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls UAC]$
QGIS:
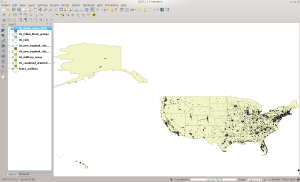
UAC in QGIS
Next we will do the PRIMARYROADS dataset, which can be thought of as basically major US Interstates.
[bmaddox@girls census]$ ls -l PRIMARYROADS/
total 25364
-rwxrw-r-x 1 bmaddox bmaddox 25969141 Aug 16 2013 tl_2013_us_primaryroads.zip
[bmaddox@girls census]$ cd PRIMARYROADS/
[bmaddox@girls PRIMARYROADS]$ ls -l
total 25364
-rwxrw-r-x 1 bmaddox bmaddox 25969141 Aug 16 2013 tl_2013_us_primaryroads.zip
[bmaddox@girls PRIMARYROADS]$ unzip tl_2013_us_primaryroads.zip
Archive: tl_2013_us_primaryroads.zip
inflating: tl_2013_us_primaryroads.dbf
inflating: tl_2013_us_primaryroads.prj
inflating: tl_2013_us_primaryroads.shp
inflating: tl_2013_us_primaryroads.shp.xml
inflating: tl_2013_us_primaryroads.shx
[bmaddox@girls PRIMARYROADS]$ ls -l
total 66828
-rwxrwxr-x 1 bmaddox bmaddox 1633818 Aug 6 2013 tl_2013_us_primaryroads.dbf
-rwxrwxr-x 1 bmaddox bmaddox 165 Aug 6 2013 tl_2013_us_primaryroads.prj
-rwxrwxr-x 1 bmaddox bmaddox 40696696 Aug 6 2013 tl_2013_us_primaryroads.shp
-rwxrwxr-x 1 bmaddox bmaddox 16481 Aug 6 2013 tl_2013_us_primaryroads.shp.xml
-rwxrwxr-x 1 bmaddox bmaddox 101412 Aug 6 2013 tl_2013_us_primaryroads.shx
-rwxrw-r-x 1 bmaddox bmaddox 25969141 Aug 16 2013 tl_2013_us_primaryroads.zip
[bmaddox@girls PRIMARYROADS]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_primaryroads.shp US_Primary_Roads |psql -d Census_2013 Shapefile type: Arc
Postgis type: MULTILINESTRING[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_primary_roads_gid_seq" for serial column "us_primary_roads.gid" CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_primary_roads_pkey" for table "us_primary_roads"
ALTER TABLE
addgeometrycolumn
---------------------------------------------------------------------
public.us_primary_roads.geom SRID:4269 TYPE:MULTILINESTRING DIMS:2 (1 row)
CREATE INDEX
COMMIT
[bmaddox@girls PRIMARYROADS]$
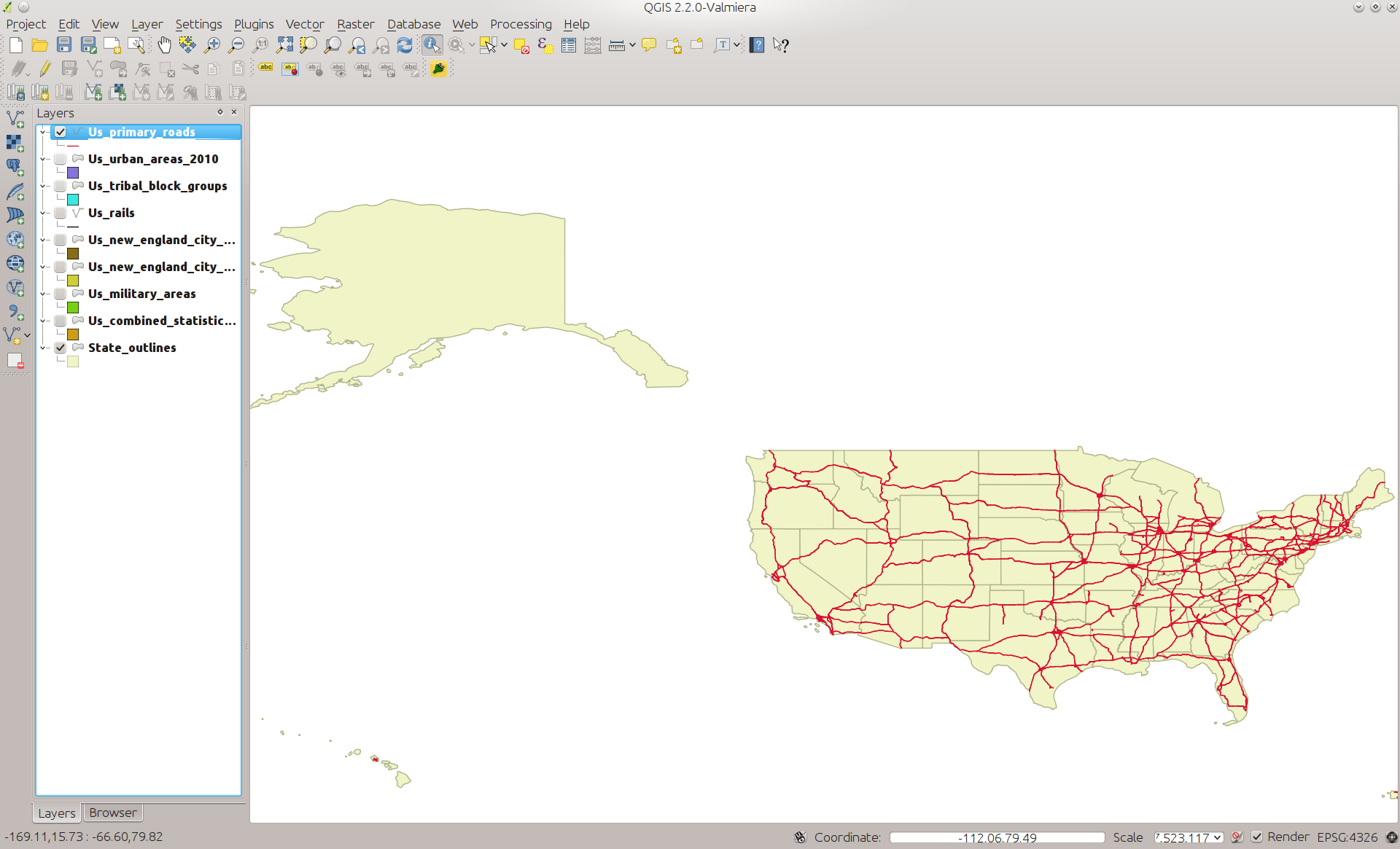
And in QGIS:

PRIMARYROADS in QGIS
And finally (yes FINALLY!), the ZCTA5 dataset, which is the list of US zip code tabulation areas.
[bmaddox@girls census]$ cd ZCTA5/
[bmaddox@girls ZCTA5]$ dir
total 513180
-rwxrw-r-x 1 bmaddox bmaddox 525492077 Aug 16 2013 tl_2013_us_zcta510.zip
[bmaddox@girls ZCTA5]$ unzip tl_2013_us_zcta510.zip
Archive: tl_2013_us_zcta510.zip
inflating: tl_2013_us_zcta510.dbf
inflating: tl_2013_us_zcta510.prj
inflating: tl_2013_us_zcta510.shp
inflating: tl_2013_us_zcta510.shp.xml
inflating: tl_2013_us_zcta510.shx
[bmaddox@girls ZCTA5]$ shp2pgsql -s 4269 -c -D -I -WLATIN1 tl_2013_us_zcta510.shp US_Zip_Code_Areas |psql -d Census_2013
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
SET
SET
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "us_zip_code_areas_gid_seq" for serial column "us_zip_code_areas.gid"
CREATE TABLE
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "us_zip_code_areas_pkey" for table "us_zip_code_areas"
ALTER TABLE
addgeometrycolumn
------------------------------------------------------------------- public.us_zip_code_areas.geom SRID:4269 TYPE:MULTIPOLYGON DIMS:2
(1 row)
CREATE INDEX
COMMIT
[bmaddox@girls ZCTA5]$
And the final screen shot:
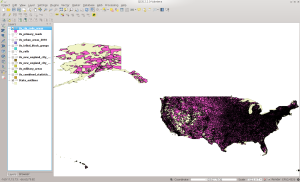
ZCTA5 in QGIS
So that is it. You now have the US state borders, county outlines, and a large amount of national-level data such as railroads and interstates. In 8.3 we will tackle some of the other datasets that are comprised of multiple county files for each state. We will convert them to single state files and then import them into PostGIS. Until then, examine and experiment with what you have just done and see what data is actually inside the tables.